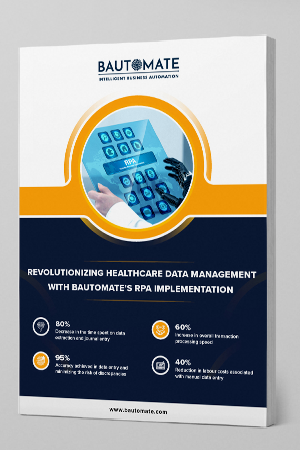
OCR Overview:
OCR (Optical Character Recognition) also termed Optical Character Reader is a software system that is capable of recognizing of alphanumeric characters either in printed or handwritten or image formats. Such a system performs a quick scan of characters. The term Intelligent Character Recognition (ICR) has been used, of late, to describe the process of interpretation of data and characters from unstructured/structured input sources.
The OCR system consists of a set of algorithms that make out the embedded text in a scanned image and convert it into a text in human editable format. The fact that a good OCR Software is capable of recognizing text belonging to any language of the world is astounding !! For recognition of a wide range of text the Intelligent character recognition software uses algorithms such as segmentation, feature extraction, and recognition. In order to appraise the performance of OCR, we need to try the software with multi-style, multi-font & multi-sized text images. It is also remarkable that good data extraction software improves its performance with usage and hence it should be tried various input sources. By dint of its cognitive skills, the system can perform validation of data, elimination of documents & many other value-added tasks.
Different types of OCR techniques:
There are various nuances to be considered when it comes to character recognition.
- De-skew – This technique senses the positioning of the source document and adjusts its scan in a clockwise or anti-clockwise direction to make lines of text perfectly horizontal or vertical.
- Despeckle – The ability of RPA software to remove positive and negative spots & make the edges leveled.
- Binarization – RPA software can convert a colored image to black-and-white (binary image). The task of binarization is performed as a simple way of separating the text (or other image components of your wish) from the background. Binarization is an essential technique since most commercial recognition algorithms currently available in the market work only on binary images as extraction from such images is relatively easier. The efficacy of the binarization step will have a voice in the quality of the final output to a significant extent. Hence the buyers need to exercise caution on the power of the binarization technique of the data extraction software if you require data extraction from scenery images or old documents.
- Line removal – The technique cleans up non-glyph boxes and lines. Glyph refers to a picture or symbol that represents a word, used in some writing systems, similar to the one used in ancient Egypt.
- Layout analysis or “zoning” – It is a technique in which columns, paragraphs, captions, etc. are identified as distinct blocks. Especially important in multi-column layouts and tables.
- Line and word detection – Sets up a baseline for word and character shapes, separates words if necessary.
- Script recognition – There may be cases where a document features content in multiple languages. In such a case, the identification of words is necessary to invoke the correct script or module.
- Character isolation or “segmentation” – Multiple characters may be connected in cursive handwriting or there might be ambiguities regarding interpretation. In such a scenario, the individual characters must be separated. The process may also require the breaking down of single characters into multiple pieces. Finally, the characters must be displayed in the correct sequence in the output file.
- Normalization of aspect ratio and scale.
- Text recognition – matrix matching: It involves comparing an image to a stored glyph on a pixel-by-pixel basis through the “pattern matching”, “pattern recognition”, or “image correlation” process. The process involves the isolation of the input glyph from the rest of the image, and the extracted glyph is stored in a similar font and at the same scale. This technique works best with typewritten text and struggles when new fonts are encountered. This is now an obsolete technique.
- Text recognition – feature extraction: It separates glyphs into features such as lines, line direction, loose loops, and line intersections. The extraction features reduce the dimensionality of the representation and make the recognition process computationally efficient.
These features are compared with an abstract vector-like representation of a character, which might reduce to one or more glyph prototypes. General techniques of feature detection in computer vision are applicable to this type of data extraction technique. This technique is widely used in most modern OCR software. Nearest neighbor classifiers such as the k-nearest neighbor’s algorithm are used to compare image features with stored glyph features and choose the nearest match.
Advantages of OCR techniques in data validation:
- Great accuracy levels and elimination of manual errors
- Can detect all characters & all text is searchable
- Marked improvement in customer service
- Cost containment
- Reduced manual intervention
- Automated content processing
- Automatic classification of scanned data
- Rapid extraction and validation of data
- Scalable – Ability to handle huge volumes of data
- Storage space for the physical documents are reduced considerably
Bautomate helps in automating the tedious, paper-based workflow in document management. It is a document automation platform that has the inbuilt capabilities of RPA, OCR, DMS, and BPM modules. Contact us to know more about the product!!